Why Multiprocessing?
이전 포스트(링크)에서도 언급했듯이, Python은 Global Interpreter Lock(GIL) 로 인해서 원칙적으로는 c에서와 같이 fork 등 프로세스 분기가 막혀있다. Multiprocessing을 통해서 이런 한계점을 극복할 수 있는데, 이번 포스트에서는 그 중 Process를 이용한다.
SIMD vs Pipeline
내가 사용하는 병렬화 방식은 크게 두가지인데, 이 중 Process를 이용한 파이프라인 기반의 병렬처리는 아래 2번의 설명과 같이 한번에 처리해야하는 데이터의 양보다도 하나의 데이터에 대해 수행해야하는 작업 자체가 복잡하고 여러 단계로 이루어져 있을 때 유용하다.
- 단순한 작업이 매우 많이 반복되어야한다 --> Pool을 사용하는 SIMD스러운 병렬처리(previous post)
- 작업이 여러개의 과정으로 복잡하게 이뤄져있다 --> Process 및 Arrayqueue를 이용한 파이프라인 구축(this post)
비디오처리
비디오 처리는 2번의 좋은 예시 중 하나라고 할 수 있다. 예를 들어서 opencv에서 제공하는 1) optical flow(링크)를 실시간 비디오 스트림(30fps)에 적용해서 2) 기존 이미지와 결합시킨 다음 3) 딥러닝 모델로 action recognition을 수행하고 4) 추론 결과 및 optical flow를 오버레이로 보여주는 어플리케이션을 만들고자 하는 상황을 가정해보자. 실시간으로 생성되는 프레임 입력에 대해서 프레임 누락이나 주사율 하락(30fps 영상을 15fps로 보여준다든지)이 없이 사용자에게 보여주려면 대략 33ms 안에 한 프레임에 대한 처리 및 가시화를 수행해야한다.
1. 비디오 스트림 입력 디코딩(~3,4 ms)
2. 원하는 비디오 영역 크롭 등 전처리 및 optical flow 연산 (~20ms)
3. 딥러닝 모델 추론(~15ms)
4. cv2.imshow() 등을 이용한 시각화(~5ms)import ...
def decode_input_stream():
...
# Decode input from stream
return frame
def preprocessing(frame, previous_frame):
...
# Preprocess input
return frame, optical
def inference(model, frame, optical):
...
# Run model inference
return results
def visualize(frame, optical, results):
...
# Show results
return None
def vanilla_routine(stream):
Video = cv2.VideoCapture(stream)
while True:
frame = decode_input_stream(Video)
frame, optical = preprocessing(frame, previous_frame)
results = inference(model, frame, optical)
visualize(frame, optical, results)
if __name__ == "__main__"
vanilla_routine(stream)상기 수도코드처럼 1,2,3,4 의 과정을 단일 파이썬 프로세스가 for loop 안에서 수행하면 최대 44ms의 계산 지연이 생긴다. 이렇게 되면 들어오는 입력이 무한정으로 쌓여서 프로그램 메모리가 터지거나 쌓여있는 프레임 중 일부를 삭제해서 큐를 관리하는 별도의 루틴이 필요하게 된다. 매우 바람직하지 않은 현상이므로, 시스템 리소스가 남아있다면 병렬처리가 도움이 될 것이다.
Pipelining, 파이프라이닝
파이프라이닝이란, 아래의 그림에서 볼 수 있듯이 일반적으로 서로 독립적인 리소스를 사용하는 순차적 프로세스를 병렬적으로 돌리는 경우를 말한다. 하나하나의 작업에 대해서 시작으로부터 결과 도출까지의 시간(latency) 자체는 줄어들지 않지만 전체 작업의 관점에서는 시간당 처리량(throughput)이 증가하고 총 소요시간이 감소하는 효과가 있다.
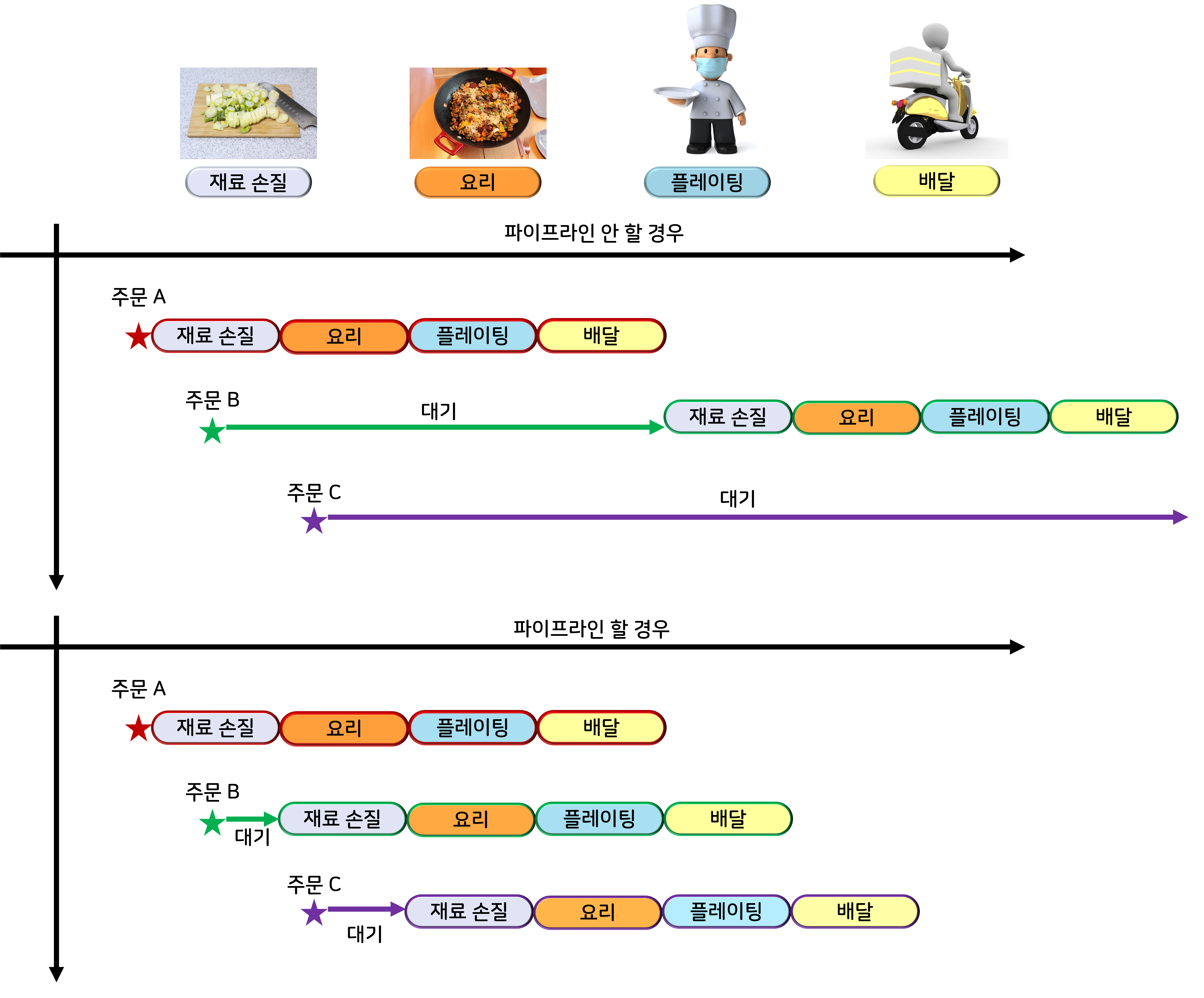
따라서, 위의 예시로 돌아오면 한 프레임 당 44ms의 지연시간이 생기는 것을 방지할 수는 없어도 전체 처리량 관점에서는 가장 오래 걸리는 2번 연산의 50fps(=20ms)를 달성할 수 있다!
ArrayQueue를 이용한 코드 예시
C 에서는 파이프라인이 상대적으로 쉬운데, 일단 fork()와 같은 프로세스 분기 명령어를 통해서 같은 정보를 공유하는 프로세스를 다수 생성하고, 각각의 process id(pid)에 의거하여 수행할 함수들을 지정해주고, 그 사이사이 데이터 이동은 pipe(예시 블로그 링크), shared_mem(예시 블로그 링크)과 같은 공유 메모리 객체를 사용하면 간단한 파이프라인이 뚝딱 만들어진다.
파이썬에서도 유사하게 접근하면 되는데, python 3.8 부터는 shared_memory 등 IPC 객체에 대한 메소드들도 지원해준다. 이번 포스트에서는 서드파티인 arrayqueue(링크)를 데이터 이동 통로로 이용하는 예시 코드를 다루지만, 다른 방식으로도 얼마든지 가능하다.
import ...
from arrayqueues.shared_arrays import ArrayQueue
import multiprocessing as mp
def decode_input_stream(Video, image_queue):
...
while True:
# Decode input from stream
flag, frame = Video.read()
image_queue.put(frame, '')
def preprocessing(image_queue,intermediate_queue1,intermediate_queue2):
...
while True:
_, _ , input = image_queue.get()
#Do Preprocessing
intermediate_queue1.put(frame_plus_optical, '')
intermediate_queue2.put(frame_plus_optical, '')
def inference(input_queue, result_queue):
...
while True:
_, _, model_input = input_queue.get()
results = model(model_input)
result_queue.put(results, '')
def visualize(overlay_queue, result_queue):
...
while True:
_, _, results = result_queue.get()
_, _, overlay = overlay_queue.get()
#Show overlay and inference results
if __name__ == "__main__"
Video = cv2.VideoCapture(stream)
image_queue = ArrayQueue(100)
intermediate_queues = [ArrayQueue(100) for _ in range(2)]
result_queue = ArrayQueue(100)
ps = []
ps.append(mp.Process(target=decode_input_stream, args=(Video,image_queue)))
ps.append(mp.Process(target=preprocessing, args=(image_queue,intermediate_queue[0],intermediate_queue[1])))
ps.append(mp.Process(target=inference, args=(intermediate_queue[0], result_queue)))
ps.append(mp.Process(target=visualize, args=(intermediate_queue[1], result_queue)))
for p in ps:
p.start()
p.join()'잡지식 저장고 > Python' 카테고리의 다른 글
| [아나콘다] 기존 환경에 environment.yml로 패키지 추가 설치하기 (0) | 2023.08.26 |
|---|---|
| 데코레이터란 : Python Decorator 예시집 - 2 (1) | 2023.03.05 |
| 데코레이터란 : Python Decorator 예시집 - 1 (5) | 2023.03.05 |
| Python setup.py 에서 닌자 관련 에러 날 때 (0) | 2021.04.13 |
| 파이썬에서 로그 한 줄에 계속 프린팅하기 (0) | 2021.04.12 |




댓글